Inside Out and Back Again Context Clues
In this blog we're going to talk virtually how to visualize, alert, and debug / troubleshoot a Kubernetes CrashLoopBackOff event. As all veteran Kubernetes users know, Kubernetes CrashLoopBackOff events are a way of life. It's happened to all of u.s.a. at to the lowest degree once and normally we're stuck scratching our heads with no access to troubleshooting tools inside the container.
Are yous in a hurry: jump directly into How to debug / troubleshoot and fix Kubernetes CrashLoopBackOff!

What is a Kubernetes CrashLoopBackOff? The meaning.
A CrashloopBackOff means that you take a pod starting, crashing, starting again, and then crashing again.
A PodSpec has a restartPolicy field with possible values Always, OnFailure, and Never which applies to all containers in a pod. The default value is E'er and the restartPolicy merely refers to restarts of the containers by the kubelet on the same node (so the restart count will reset if the pod is rescheduled in a different node). Failed containers that are restarted by the kubelet are restarted with an exponential back-off delay (10s, 20s, 40s …) capped at five minutes, and is reset later 10 minutes of successful execution. This is an instance of a PodSpec with the restartPolicy field:
apiVersion: v1 kind: Pod metadata: proper noun: dummy-pod spec: containers: - proper noun: dummy-pod image: ubuntu restartPolicy: Always 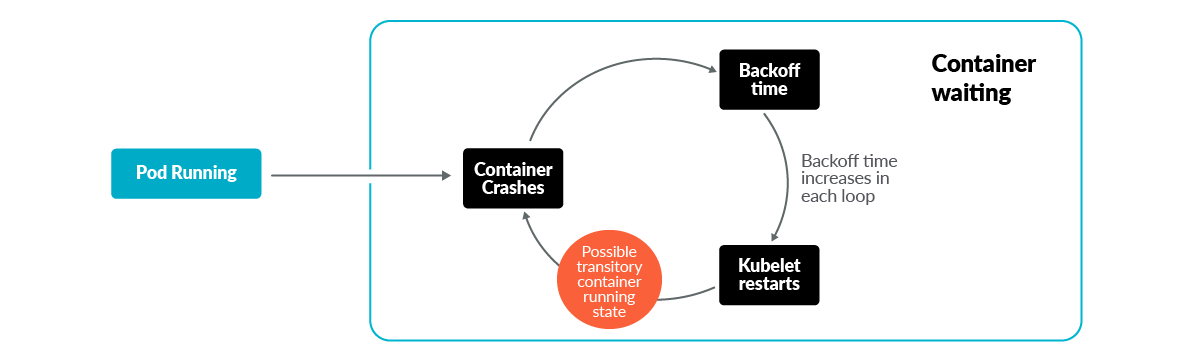
Why does a CrashLoopBackOff occur?
A quick Google search will testify us that crash loop events tin can happen for a number of different reasons (and they happen frequently). Hither are some of the umbrella causes for why they occur:
- The application within the container keeps crashing. Here, we tin can highlight several common situations:
- Error in the application configuration. A wrong value or format can make the application exit but after start.
- Bugs or non defenseless exceptions.
- One of the downstream services on which the awarding relies can't be reached or the connection fails (database, backend, etc.).
- Errors in the manifest or pod configuration, such as:
- Trying to demark an already used port.
- Wrong command arguments for the container.
- Errors in liveness probes.
- Read-just filesystem.
How can I run into if there are CrashLoopBackOff in my cluster?
Run your standard kubectl go pods command and you'll be able to see the condition of any pod that is currently in CrashLoopBackOff:
kubectl get pods --namespace nginx-crashloop Name Fix STATUS RESTARTS AGE flask-7996469c47-d7zl2 ane/1 Running 1 77d flask-7996469c47-tdr2n 1/1 Running 0 77d nginx-5796d5bc7c-2jdr5 0/i CrashLoopBackOff 2 1m nginx-5796d5bc7c-xsl6p 0/1 CrashLoopBackOff 2 1m Really if you encounter pods in Fault condition, probably they volition get into CrashLoopBackOff soon:
kubectl get pods --namespace nginx-crashloop NAME Gear up STATUS RESTARTS AGE flask-7996469c47-d7zl2 ane/i Running ane 77d flask-7996469c47-tdr2n 1/one Running 0 77d nginx-5796d5bc7c-2jdr5 0/1 Error 0 24s nginx-5796d5bc7c-xsl6p 0/1 Fault 0 24s Doing a kubectl describe pod will give us more information on that pod:
kubectl depict pod nginx-5796d5bc7c-xsl6p --namespace nginx-crashloop Proper name: nginx-5796d5bc7c-xsl6p Namespace: nginx-crashloop Node: ip-10-0-nine-132.us-eastward-2.compute.internal/10.0.9.132 First Time: Tue, 27 Mar 2018 19:11:05 +0200 Labels: app=nginx-crashloop name=nginx pod-template-hash=1352816737 role=app Annotations: kubernetes.io/created-by={"kind":"SerializedReference","apiVersion":"v1","reference":{"kind":"ReplicaSet","namespace":"nginx-crashloop","proper name":"nginx-5796d5bc7c","uid":"fb9e9518-f542-11e7-a8f2-065cff0... Status: Running IP: ten.47.0.fifteen Controlled By: ReplicaSet/nginx-5796d5bc7c Containers: nginx: Container ID: docker://513cab3de8be8754d054a4eff45e291d33b63e11b2143d0ff782dccc286ba05e Image: nginx Image ID: docker-pullable://[email protected]:c4ee0ecb376636258447e1d8effb56c09c75fe7acf756bf7c13efadf38aa0aca Port: <none> Country: Waiting Reason: CrashLoopBackOff Last State: Terminated Reason: Fault Exit Code: 1 Started: Tue, 27 Mar 2018 xix:13:15 +0200 Finished: Tue, 27 Mar 2018 19:xiii:16 +0200 Ready: False Restart Count: four Surround: <none> Mounts: /etc/nginx/nginx.conf from config (rw) /var/run/secrets/kubernetes.io/serviceaccount from default-token-chcxn (ro) Conditions: Type Status Initialized True Ready False PodScheduled True Volumes: config: Blazon: ConfigMap (a volume populated by a ConfigMap) Proper name: nginxconfig Optional: simulated default-token-chcxn: Blazon: Secret (a volume populated past a Hugger-mugger) SecretName: default-token-chcxn Optional: faux QoS Course: BestEffort Node-Selectors: nginxcrash=allowed Tolerations: node.alpha.kubernetes.io/notReady:NoExecute for 300s node.alpha.kubernetes.io/unreachable:NoExecute for 300s Events: Blazon Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 2m default-scheduler Successfully assigned nginx-5796d5bc7c-xsl6p to ip-10-0-nine-132.u.s.-due east-2.compute.internal Normal SuccessfulMountVolume 2m kubelet, ip-10-0-9-132.us-east-2.compute.internal MountVolume.SetUp succeeded for volume "config" Normal SuccessfulMountVolume 2m kubelet, ip-10-0-ix-132.us-east-2.compute.internal MountVolume.SetUp succeeded for book "default-token-chcxn" Normal Pulled 1m (x3 over 2m) kubelet, ip-10-0-9-132.us-due east-two.compute.internal Successfully pulled prototype "nginx" Normal Created 1m (x3 over 2m) kubelet, ip-10-0-9-132.us-east-ii.compute.internal Created container Normal Started 1m (x3 over 2m) kubelet, ip-10-0-nine-132.the states-e-ii.compute.internal Started container Warning BackOff 1m (x5 over 1m) kubelet, ip-10-0-9-132.us-due east-two.compute.internal Dorsum-off restarting failed container Alarm FailedSync 1m (x5 over 1m) kubelet, ip-10-0-9-132.us-east-2.compute.internal Fault syncing pod Normal Pulling 57s (x4 over 2m) kubelet, ip-10-0-9-132.u.s.a.-east-2.compute.internal pulling paradigm "nginx" Important things we can extract from the output of the describe control:
- Pod status phase is RUNNING
- Container state is WAITING
- Container state reason is CRASHLOOPBACKOFF
- Last container terminated with error (fault code i)
- kubelet is generating an event every time the container is restarted, delayed with a Back-off time.
From here, nosotros have several lines of investigation:
- Kubernetes events
- Container logs
- Container organization calls
Visualizing Kubernetes events in Sysdig Monitor
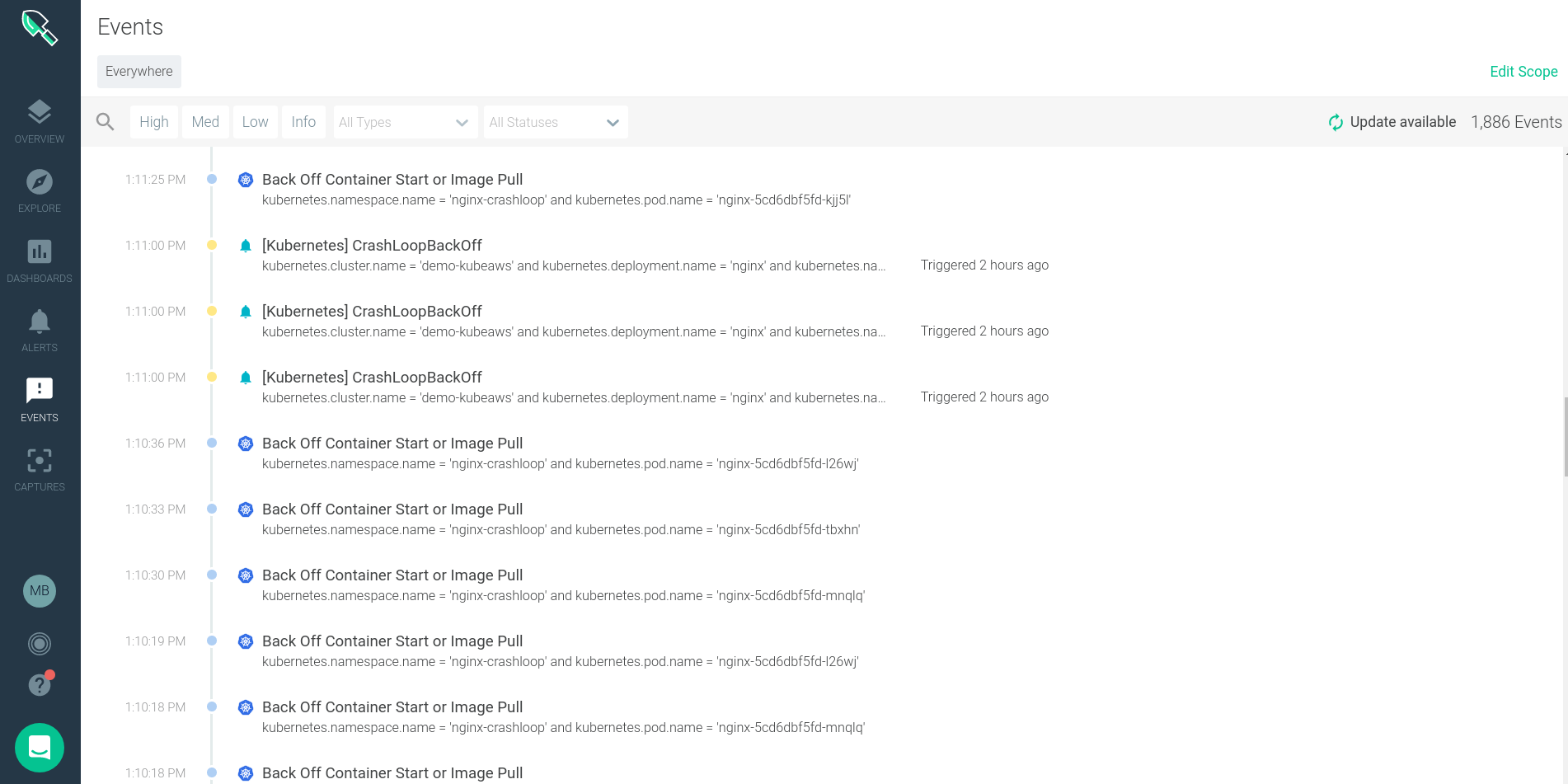
CrashLoopBackOff events can be viewed through Sysdig Monitor on the events tab. Sysdig Monitor will natively ingest both Kubernetes and Docker events for users alert on, and overlay on charts of the system performance.
Kubernetes Events Ingested by Sysdig
kubernetes: node: - TerminatedAllPods # Terminated All Pods (information) - RegisteredNode # Node Registered (information)* - RemovingNode # Removing Node (information)* - DeletingNode # Deleting Node (information)* - DeletingAllPods # Deleting All Pods (data) - TerminatingEvictedPod # Terminating Evicted Pod (information)* - NodeReady # Node Gear up (information)* - NodeNotReady # Node not Ready (information)* - NodeSchedulable # Node is Schedulable (information)* - NodeNotSchedulable # Node is not Schedulable (information)* - CIDRNotAvailable # CIDR not Available (data)* - CIDRAssignmentFailed # CIDR Assignment Failed (information)* - Starting # Starting Kubelet (data)* - KubeletSetupFailed # Kubelet Setup Failed (warning)* - FailedMount # Volume Mount Failed (alert)* - NodeSelectorMismatching # Node Selector Mismatch (warning)* - InsufficientFreeCPU # Insufficient Free CPU (warning)* - InsufficientFreeMemory # Insufficient Free Mem (warning)* - OutOfDisk # Out of Disk (information)* - HostNetworkNotSupported # Host Ntw not Supported (warning)* - NilShaper # Undefined Shaper (warning)* - Rebooted # Node Rebooted (warning)* - NodeHasSufficientDisk # Node Has Sufficient Disk (information)* - NodeOutOfDisk # Node Out of Disk Space (information)* - InvalidDiskCapacity # Invalid Deejay Chapters (warning)* - FreeDiskSpaceFailed # Free Deejay Space Failed (alert)* pod: - Pulling # Pulling Container Epitome (data) - Pulled # Ctr Img Pulled (information) - Failed # Ctr Img Pull/Create/Beginning Neglect (warning)* - InspectFailed # Ctr Img Inspect Failed (warning)* - ErrImageNeverPull # Ctr Img NeverPull Policy Violate (warning)* - BackOff # Back Off Ctr Start, Image Pull (alarm) - Created # Container Created (information) - Started # Container Started (information) - Killing # Killing Container (data)* - Unhealthy # Container Unhealthy (warning) - FailedSync # Pod Sync Failed (warning) - FailedValidation # Failed Pod Config Validation (alert) - OutOfDisk # Out of Disk (data)* - HostPortConflict # Host/Port Conflict (warning)* replicationController: - SuccessfulCreate # Pod Created (information)* - FailedCreate # Pod Create Failed (warning)* - SuccessfulDelete # Pod Deleted (information)* - FailedDelete # Pod Delete Failed (warning)* Custom events can be sent into the Sysdig Monitor events API to exist used for correlation and alerting besides. For example yous can transport a custom event when you run a new deployment from Jenkins, when you exercise a whorl-back of a broken version or when your deject infrastructure changes.
The custom events section of Sysdig Monitor gives us a feed of all events that have happened across my distributed Kubernetes surround. Hither we can see the timestamp, issue name, description, severity and other details.
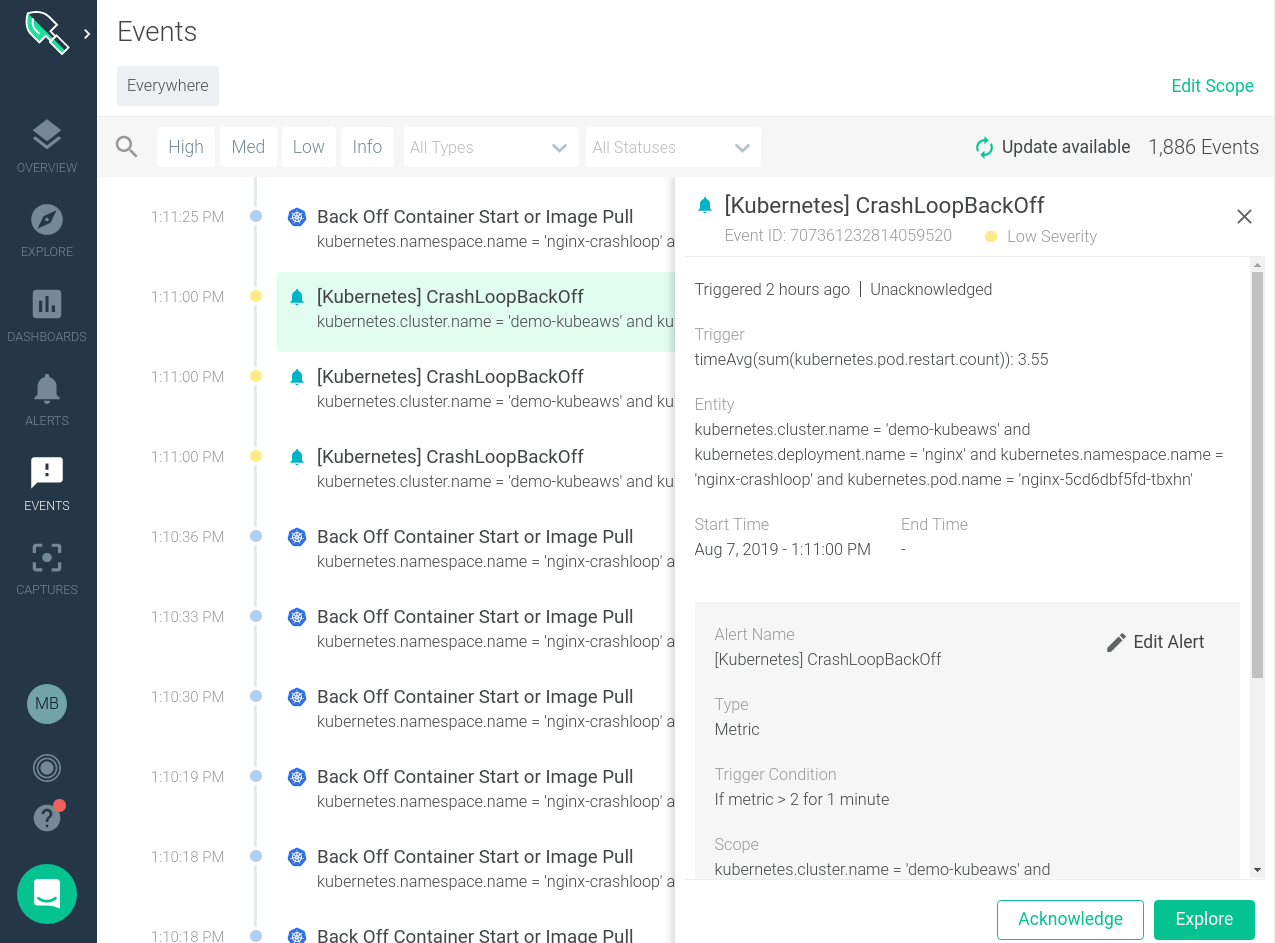
Clicking on an individual issue brings up further details virtually that specific upshot and more granular details about where it occurred in our infrastructure.
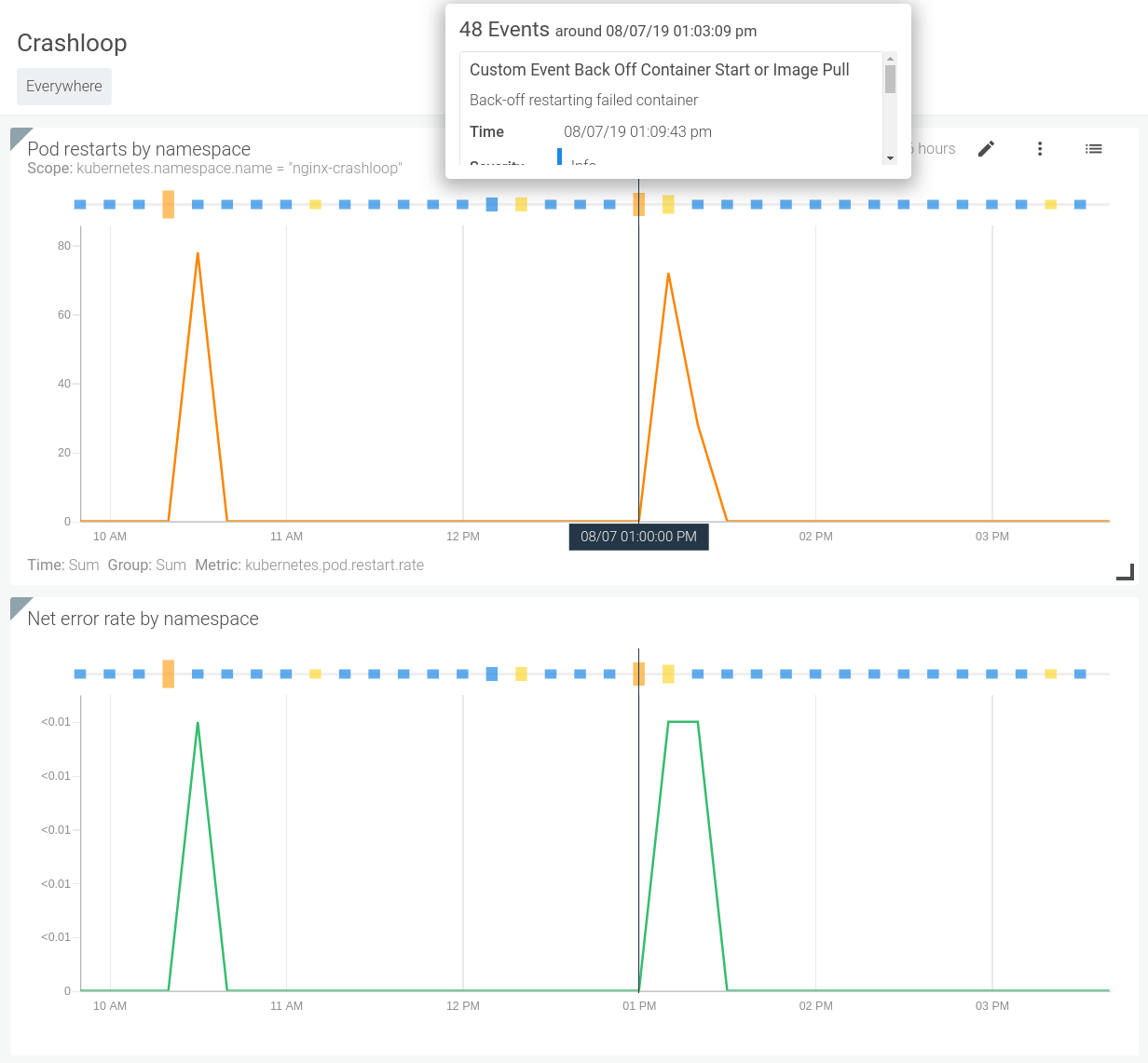
Nosotros tin can also correlate these events with the beliefs of our systems. Looking at the image beneath nosotros tin can quickly see when a specific backoff outcome occurred and if it caused and modify to the functioning of the organisation.
How to warning on Kubernetes CrashLoopBackOff
For alerting purposes we'll want to use the metric kubernetes.pod.restart.rate. This will give united states the ability to practise assay on the trend of pod restarts over time, and promptly notify our team of any anomalies.
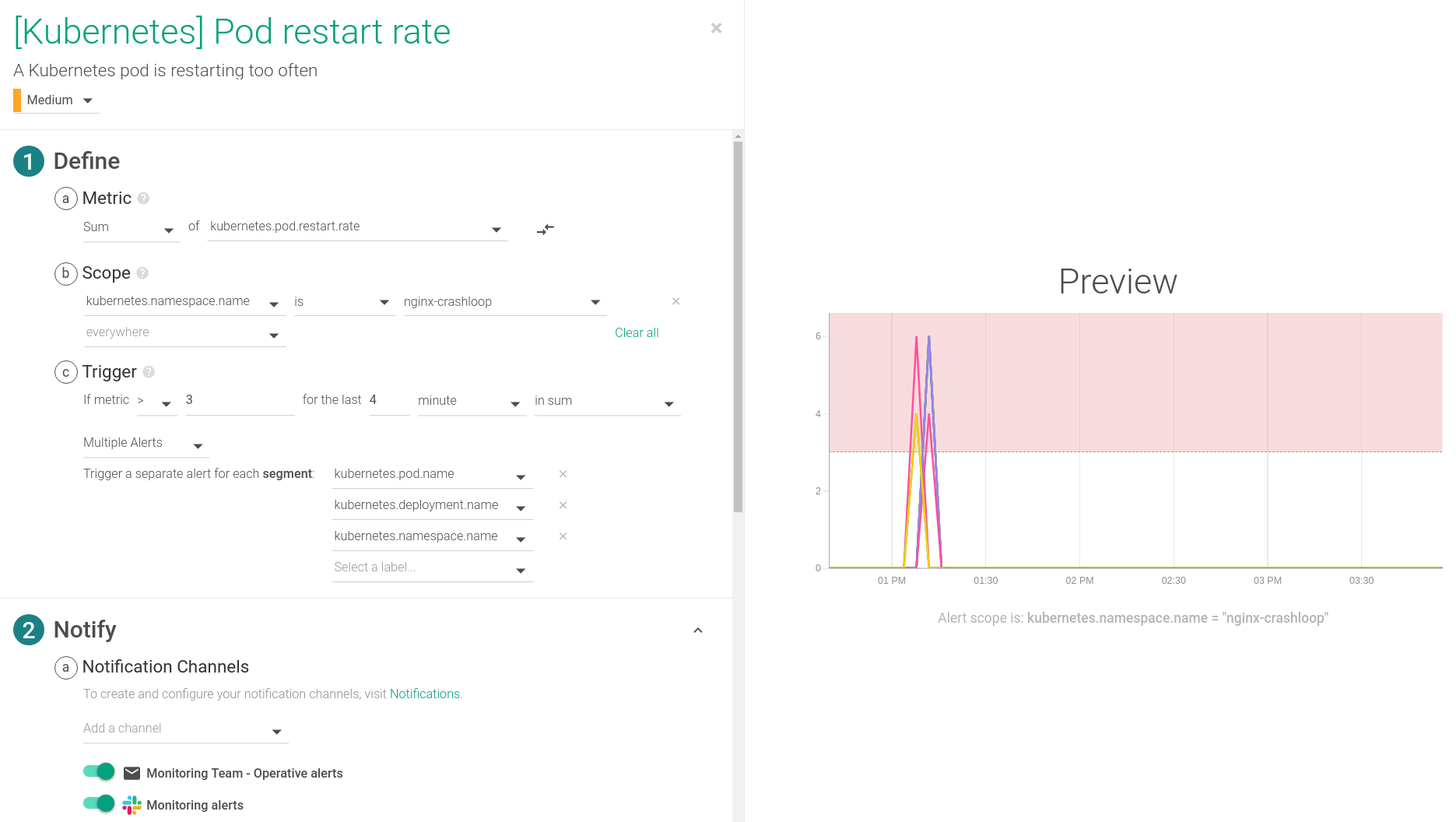
Depending on the delay in your environment you lot'll want to toggle the time settings. This warning is configured to trigger if whatsoever pod restarts more than 3 times over a 4 minute span, which is ordinarily an indicator of a CrashLoopBackOff event. This alert is ane of the default alerts for Kubernetes environments.
Enabling a Sysdig Capture is too very important for the troubleshooting of a CrashLoopBackOff. A Sysdig capture is a total recording of everything that happened on the system at the indicate in time when an warning triggered. Captures can be opened with Sysdig Inspect for deep forensic and troubleshooting analysis so teams can respond and recover from incidents quicker.
In a similar fashion, you can also configure a CrashLoopBackOff alert based on the events that Sysdig collects:
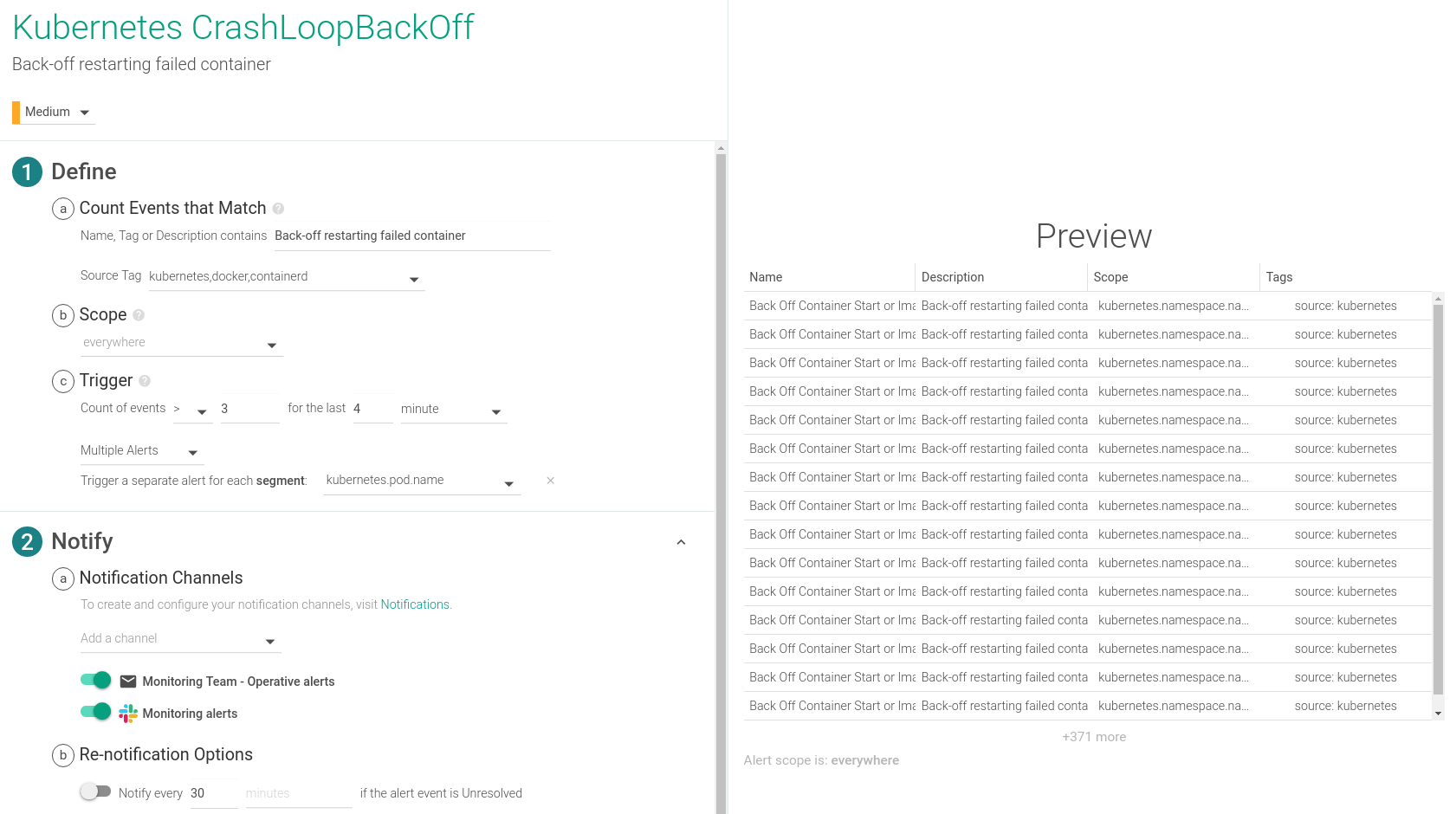
How to debug / troubleshoot and fix Kubernetes CrashLoopBackOff
You tin can manually trigger a Sysdig capture at any signal in time by selecting the host where y'all see the CrashLoopBackOff is occurring and starting the capture. You can have information technology manually with Sysdig open source if y'all have information technology installed on that host. But here will take advantage of the Sysdig Monitor capabilities that tin automatically take this capture file as a response to an warning, in this instance a CrashLoopBackOff alert.
The first troubleshooting action particular is to open the capture file that was recorded at the point in time that the result was happening on the host.

When a capture is opened in Sysdig Monitor a browser window will pop upward with Sysdig Inspect. Inspect allows you to practise organisation call analysis through a GUI for more efficient correlation and troubleshooting assay. Inside the scope of our Sysdig Secure, our container run-time security product, Sysdig Inspect is used for mail-mortem assay and forensics.
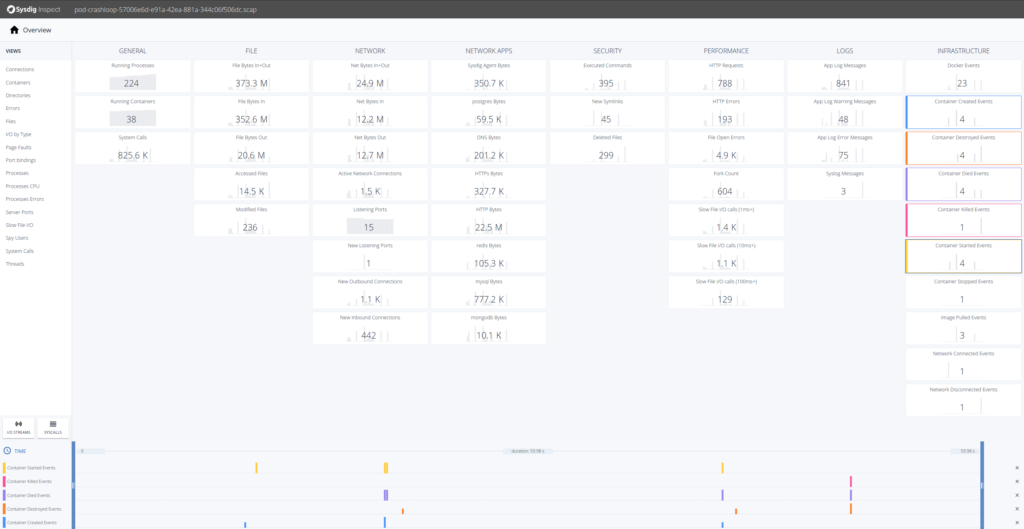
To troubleshoot this event we'll want to await at everything that is occurring the infrastructure column of Sysdig Inspect. Selecting the Docker Events tiles will bring those events into the timeline at the bottom.
Let's try to troubleshoot what's going on here. A good commencement pace is to drill downwardly into Container Died Events.
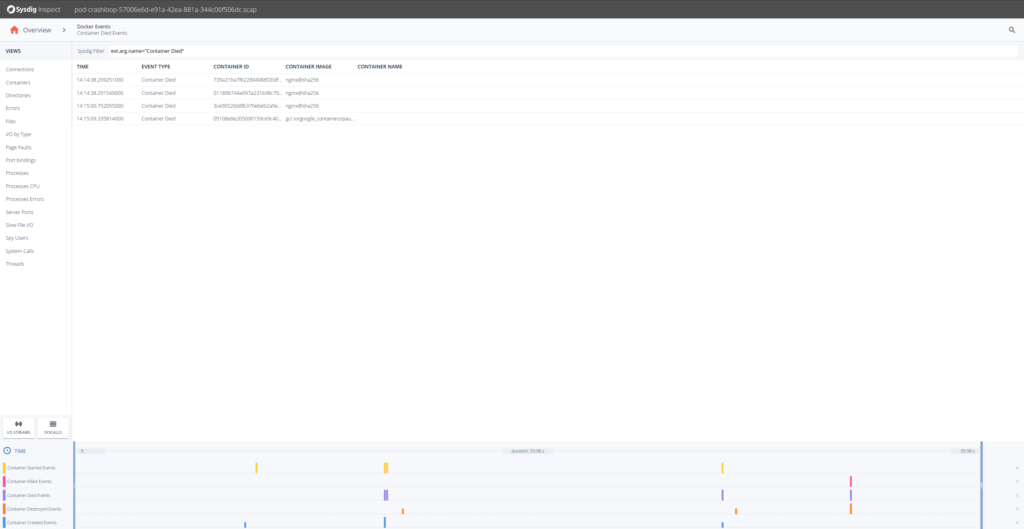
OK, so it seems that the Nginx containers are having trouble. Looking at the timestamps they die presently after being created. Let's drill downward in whatever of the Nginx containers and at that place select Processes on the left hand side.
We know our Nginx container only executes one process "nginx" so from the Processes filter past proc.name = nginx.
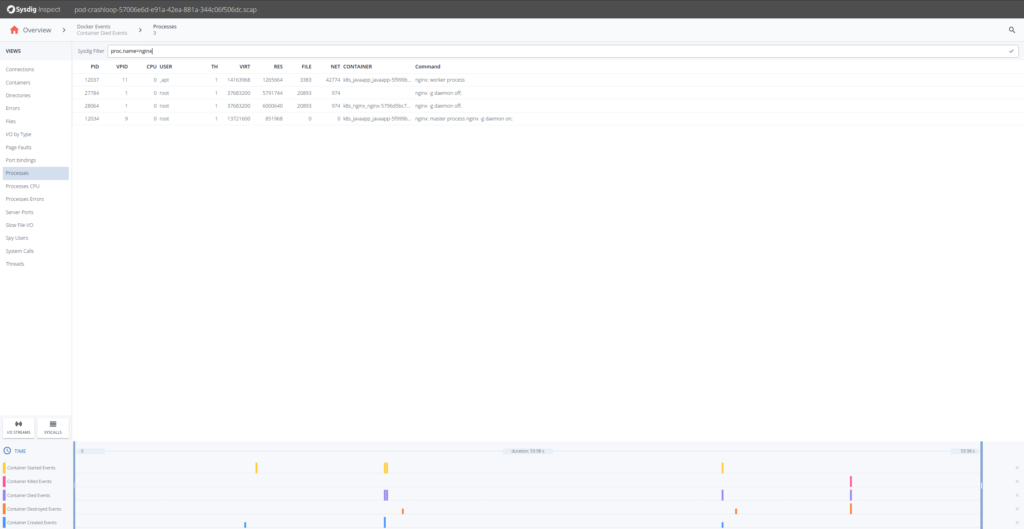
Sysdig Inspect filters use the Sysdig open up-source syntax and can be used to pinpoint action.
We tin can click on the Errors section, but nothing pregnant appears there, no failed system calls. Let's move into the Files section to inspect file arrangement activity. There will come across a error.log file, that probably has some data for us. We can see its I/O action clicking on the I/O Streams icon.
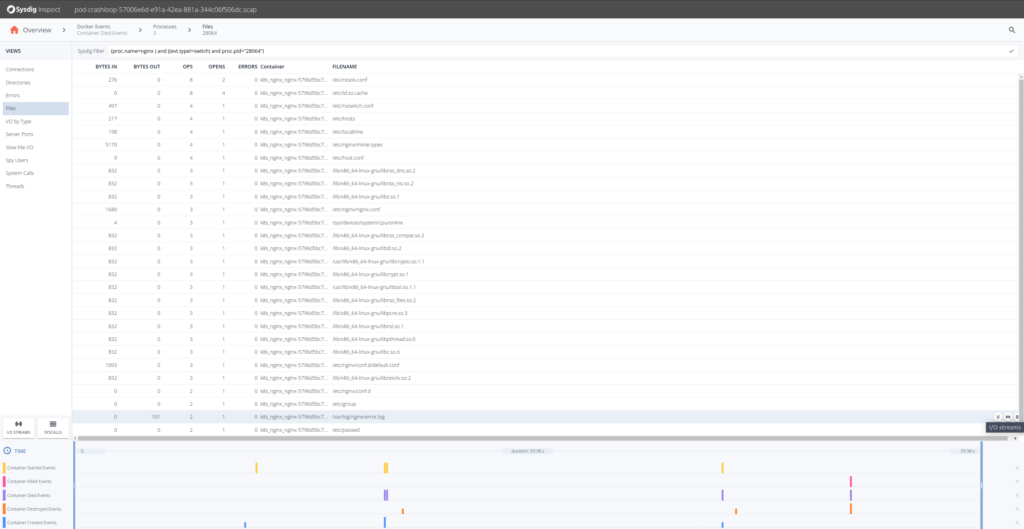
So from the content written in the error.log file until the container died, appears that Nginx cannot resolve a configured upstream server. We know why the Nginx fails, simply can we expect at what was the configured DNS server for that pod? Sure, just go dorsum and get the streams for resolv.conf.
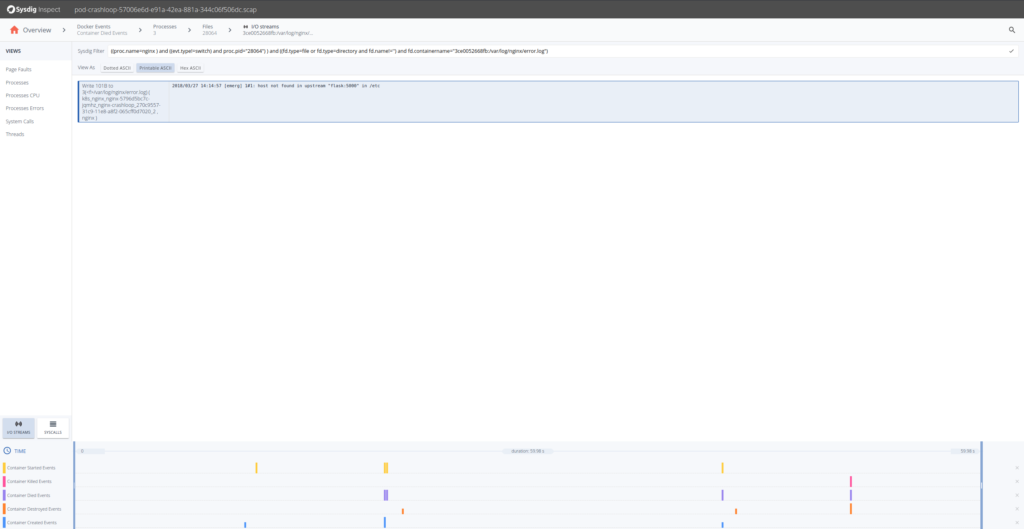
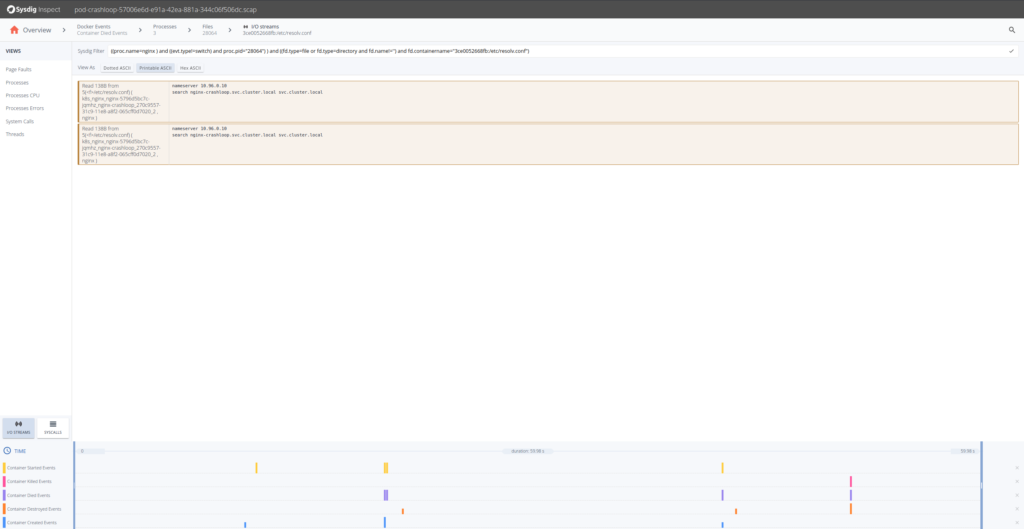
From here nosotros can go fifty-fifty further and look at the DNS requests 53/UDP, and seems that the response was not found. This gives us further troubleshooting clues: we deployed the Nginx ReplicaSets first and the upstream Kubernetes service later. Nginx has a particularity, information technology caches the proxy names (like "flask") at startup time, not upon client asking. In other words, we have deployed the dissimilar Kubernetes entities in the incorrect dependency order.
Conclusion
While something like a pod restarting is an piece of cake affair to spot, responding and recovering apace from a potential degradation in a production service can be much harder, especially when the logs from the container are gone, you cannot reproduce the trouble outside a specific environment or you but don't have the troubleshooting tools inside the container.
This is why further troubleshooting preparations similar Sysdig captures are needed. They provide full container context and complete visibility to any interprocess communication, files written, and network action. Like a time machine! Troubleshooting at the syscall level can be tricky but now with Sysdig Inspect it's a breeze!
You tin can sign up for a complimentary trial of Sysdig Monitor and try the out-of-the-box Kubernetes dashboards.
Source: https://sysdig.com/blog/debug-kubernetes-crashloopbackoff/
0 Response to "Inside Out and Back Again Context Clues"
Enregistrer un commentaire